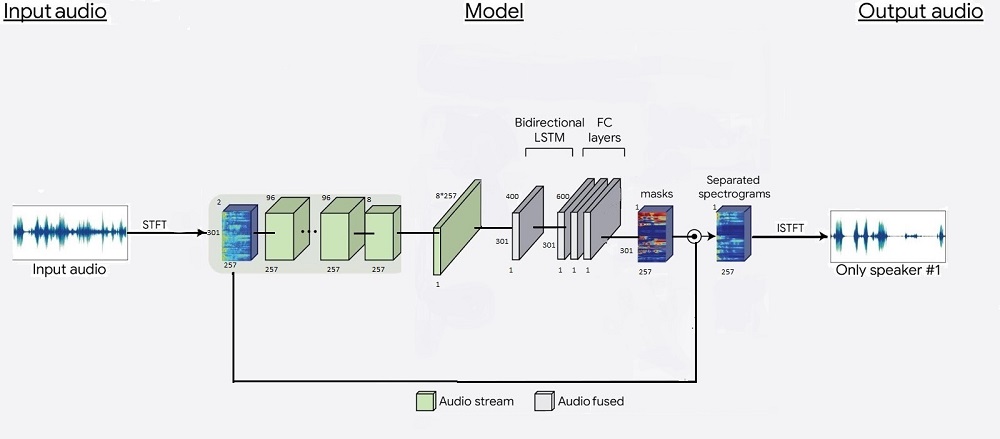
Noise is ubiquitous in almost all acoustic environments. The speech signal, that is recorded by a microphone is generally infected by noise originating from various sources.
Such contamination can change the characteristics of the speech signals and degrade the speech quality and intelligibility, thereby causing significant harm to human-to-machine communication systems.
So to improve the quality and, if possible, also the intelligibility of a noisy speech signal, speech enhancement algorithms are employed. In this work we present a deep learning based speech enhancement algorithm
which can enhance the target speech in any noisy conditions, and also can dereverb the speech signal.
A demo model for speech enhancement
The exact methodology and technique to enhance the target speech is confidential as of yet, because of its commercial viability. Once the technique becomes common, this section will be updated detailing the methods and use cases
that can be applied for enhancing the speech signals.
Below are some audio samples which are enhanced by our devoloped algorithms containing many real life scenarions.
Note: Use of headphones is recommended to asses the improvement and enhancement done by our models
Processed demo audio samples
Processed samples containing noise from varing real life scenarions: e.g, burble in reverb condition, typewritter, ambient noise, and knock on table.
Each sample is processed with 3 different models: 1) Implicit-CRM-BLSTM-Linear model 2) Implicit-CRM-BLSTM-Tanh 3) Implicit-CRM-LSTM-Linear